Say you want to take a snippet from a body of text. A fairly common task, but with a few rules if you want to do it right:
- It can never exceed n characters/words
- It can’t cut off in the middle of a word
- It doesn’t include trailing whitespace or punctuation
Although none of this is terribly difficult, it’s still a couple lines of code. On the other hand, a single regex can do all of this for you.
Snippet by Character Count
^.{0,99}\S\bThis regex gives you the first n + 1 characters (100, in this case).
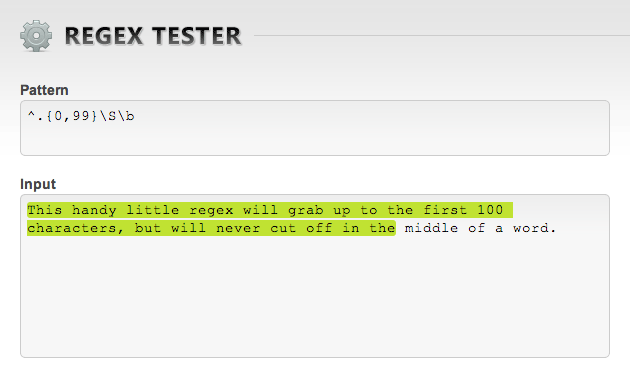
Boring technical explanation: starting at the beginning ^, grab up to 99 {0,99} characters ., but whatever is grabbed must be immediately followed by a non-whitespace character \S immediately preceding a word boundary \b.
Snippet by Word Count
^(\s?\S+){0,10}\bThis regex gives you the first n words (10, in this case).
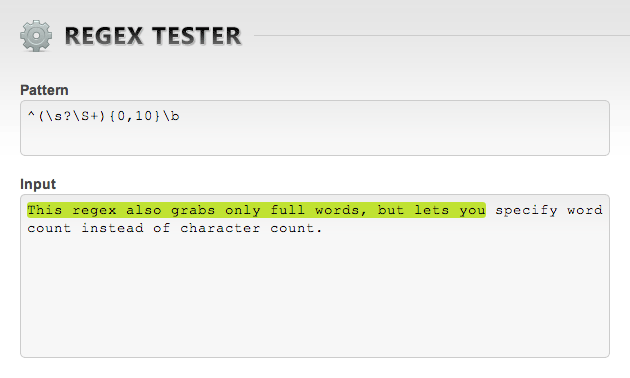
Another boring technical explanation: starting at the beginning ^, grab up to 10 {0,10} groups (). Each group may or may not start with a space \s?. Either way, each group then has 1 or more non-whitespace characters \S+. The final group must end on a word boundary \b.
Closing Remarks
Regex often walks a fine line between elegance and WTF. Personally, I’m comfortable using the 2 I’ve shared, but would never use this monstrosity. Your mileage may vary.